如果你手邊有文本資料想進行分類預測,但對模型訓練很陌生?或是你熟悉模型訓練,可是手邊的硬體資源卻無法符合訓練的需求。Google AI 平台 Vertex AI 所提供的多元解決方案,或許能解決你的問題。
Vertex AI 的 AutoML 服務能讓完全不懂 NLP 的使用者輕鬆進行預測分類,不用處理斷詞和特徵工程等前置作業。此外,Vertex AI 的 Workbench 則提供 Notebook 環境,讓有程式能力的使用者可自行編碼,並在具有高運算能力的主機上進行訓練,不用再擔心自己的電腦跑不動。本文也將依序介紹 AutoML 和 Workbench 兩種實作方法。
一、使用場景設定
假設我們是民調公司的分析師,為了要分析社群網路上藍綠的聲量趨勢,必須建構一個模型來判別文章的政治傾向。因此我們從政治人物的粉專以及粉絲團,收集具有明顯的政治色彩的文本,並選擇使用 GCP 的工具來建模。
二、Vertex AI AutoML 實作
如果對 NLP 的掌握不夠高,我們可以從 AutoML 開始著手。那就讓我們來看詳細的實作步驟。
1. 建立資料集
進入Vertex AI主畫面,選擇「建立資料集」
a. 選擇類型
點選「文字」頁籤,共會出現四個類型。
- 文字分類(單一標籤):每段文字只會有一個標籤,與其他標籤屬於互斥關係。
- 文字分類(多標籤):每段文字可以有多個標籤。
- 文字內容實體擷取:抓取文字的命名實體,如:特定名詞或動詞。
- 文字情緒分析:辨別每段文字的情緒分數,可設定範圍為 0 – 10 分。
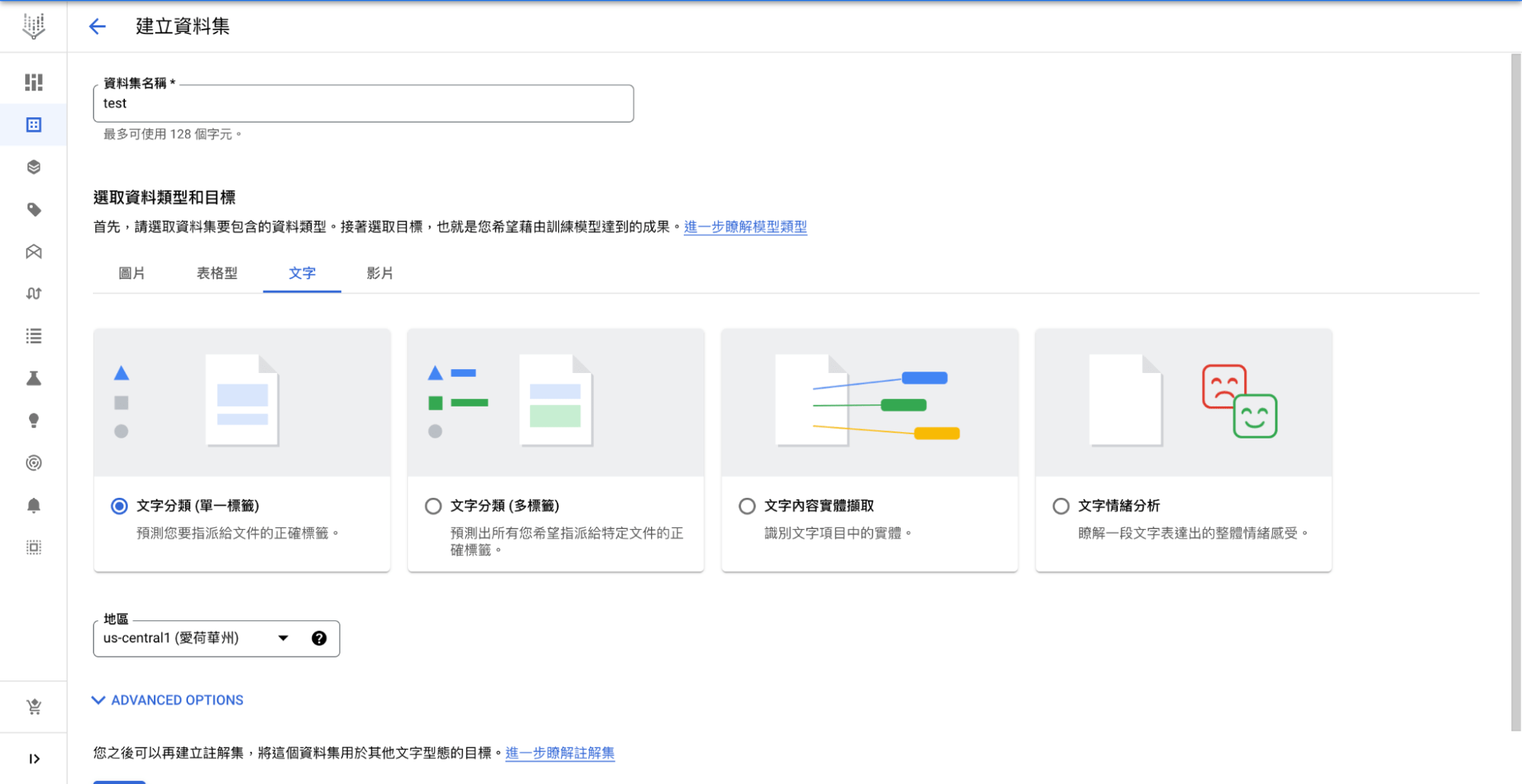
由於目標是要分辨每段文字單一的政治傾向,因此我們選擇文字分類(單一標籤),完成後往下滑點選「建立」。
b.地區選擇
地區必須選擇有提供 Vertex AI 服務的地區,如 us-central1。之後建立 Bucket 和模型最好也儲存在同一地區。
c. 準備資料
點選左側選單的「資料集」,進入剛所創建的資料集。
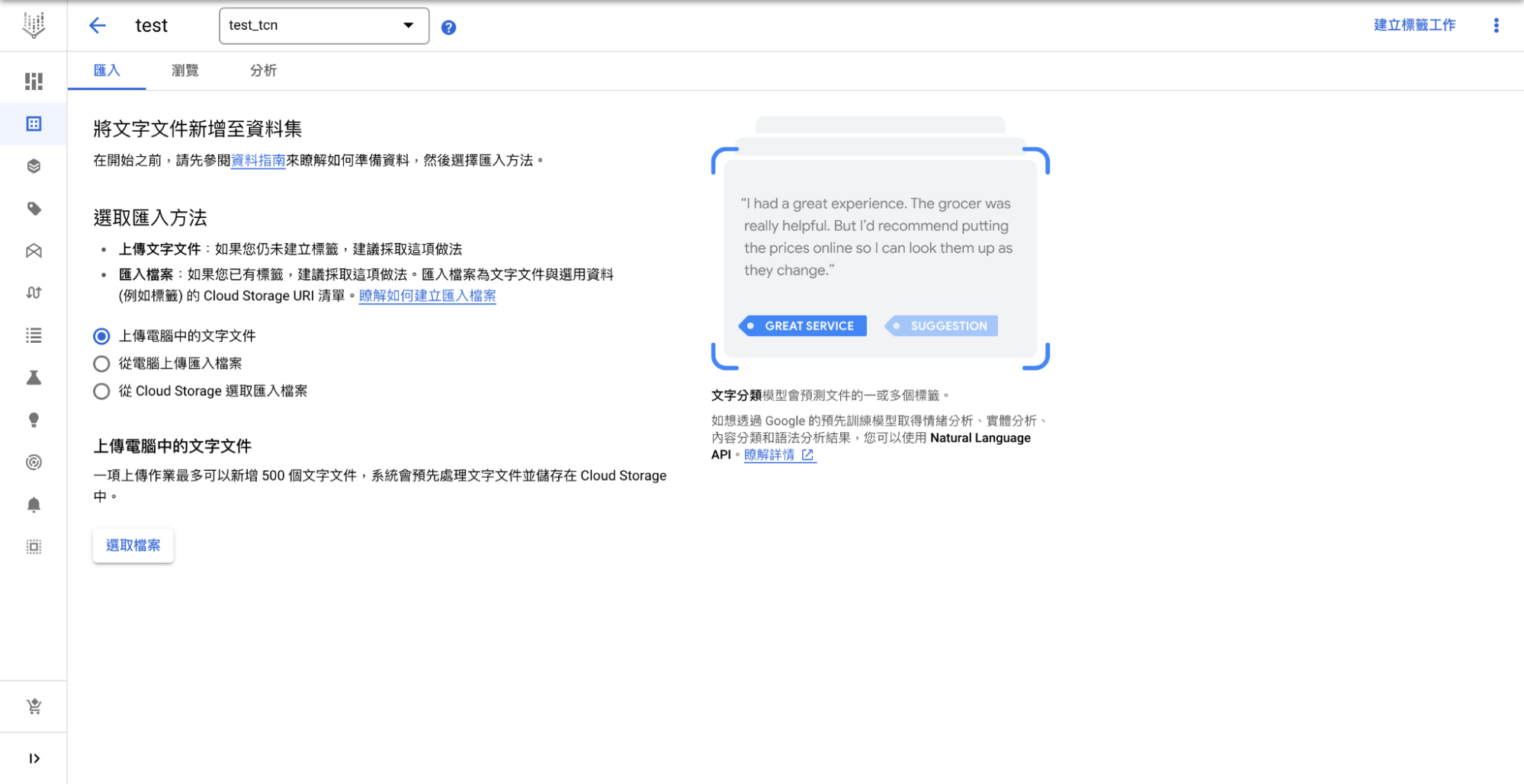
共有三種檔案上傳方式:
- 上傳電腦中的文字文件:從你的電腦上傳尚未標籤的文件,之後再到標籤頁面進行線上標籤。
- 從電腦上傳匯入檔案:這是由你的電腦上傳已標籤的文件。
- 從 Cloud Storage 選取匯入檔案:直接由 Cloud Storage 上傳檔案。
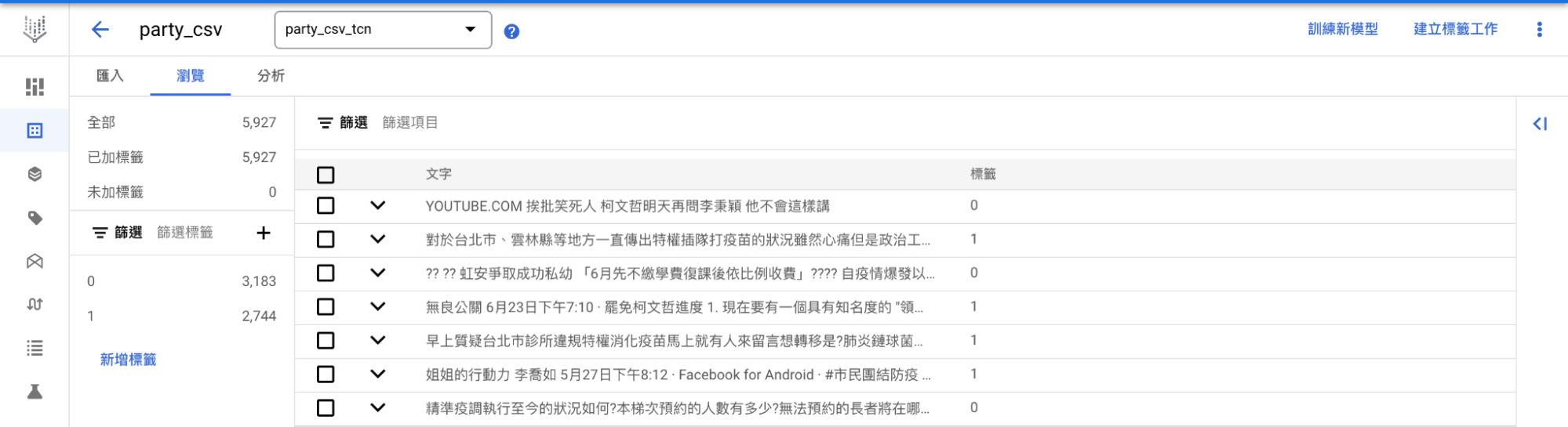
檔案格式可參照官方建議,我們使用 CSV 檔案,前幾筆內容如下,0 代表非民進黨,1 代表民進黨:

d. 匯入資料

我們使用「從電腦上傳檔案」來上傳 CSV 檔,匯入資料的同時,Google也會將你的檔案放到 Cloud Storage,因此你需要選擇 Cloud Storage 的路徑。接著就等 Google 匯入完成,本資料集約 6,000 筆,大約需要 30 分鐘。
e. 查看資料
匯入完後可檢查資料是否有正確匯入以及標籤是否有標錯
2. 訓練模型
在左側導航欄位選擇「訓練」進入訓練頁面,點選「建立」新增訓練。
a. 訓練方法
選擇剛創立的資料集還有註解集(每段文字的標籤,通常會自動幫你選好。方法則選擇 AutoML。
b. 車款詳細介紹(資料分割)
此項目名稱應該是 Google 翻譯錯誤,實際內容是指資料集的訓練、驗證和測試的比例。我們就依照 Google 的設定。
c. 等待訓練
點選「開始訓練」並等待訓練完成,本資料集訓練時間約為四小時,等待時間特別長,而且一小時就需耗費美金 3.3 元(撰稿時間 2022/2/14)
3. 檢驗模型
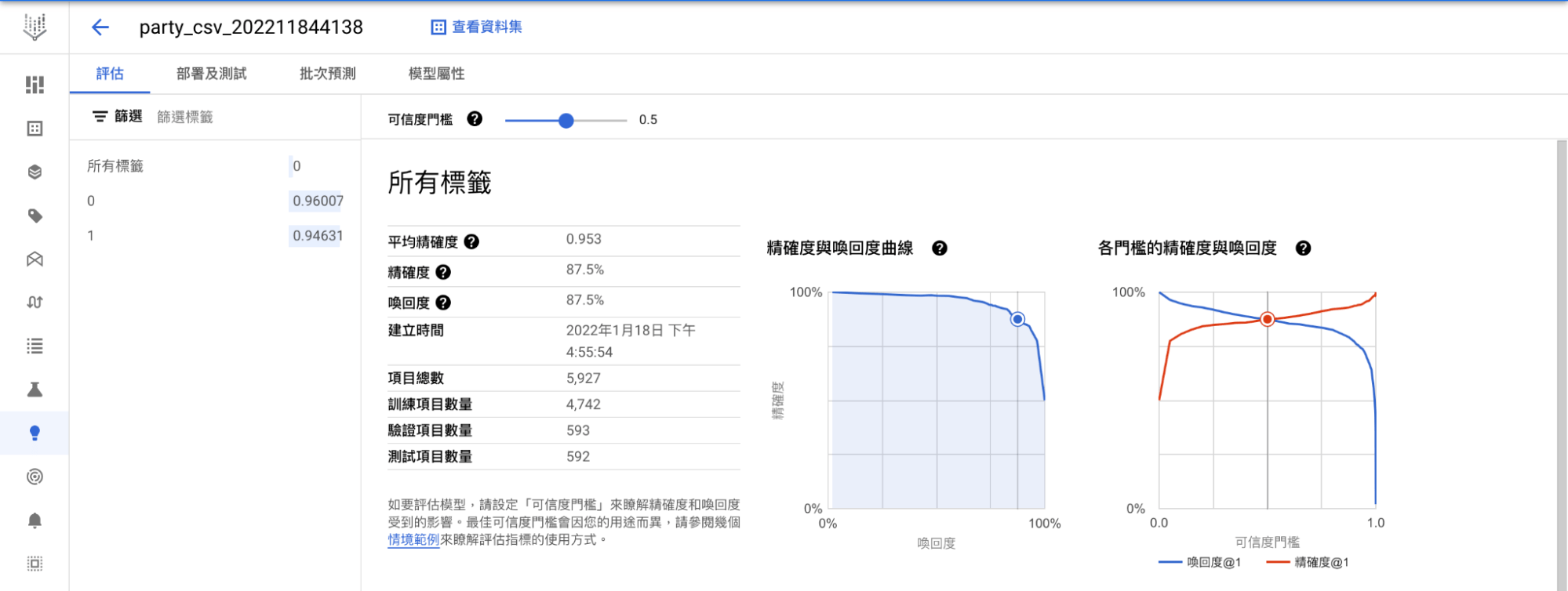
至左側選單欄選擇「模型」,就能看到平均精確度、精確度和召回率等指標,本模型平均精確度為 0.953,算是相當不錯的結果。
4. 模型部署
點選「部署及測試頁面」,按下「部署至端點」
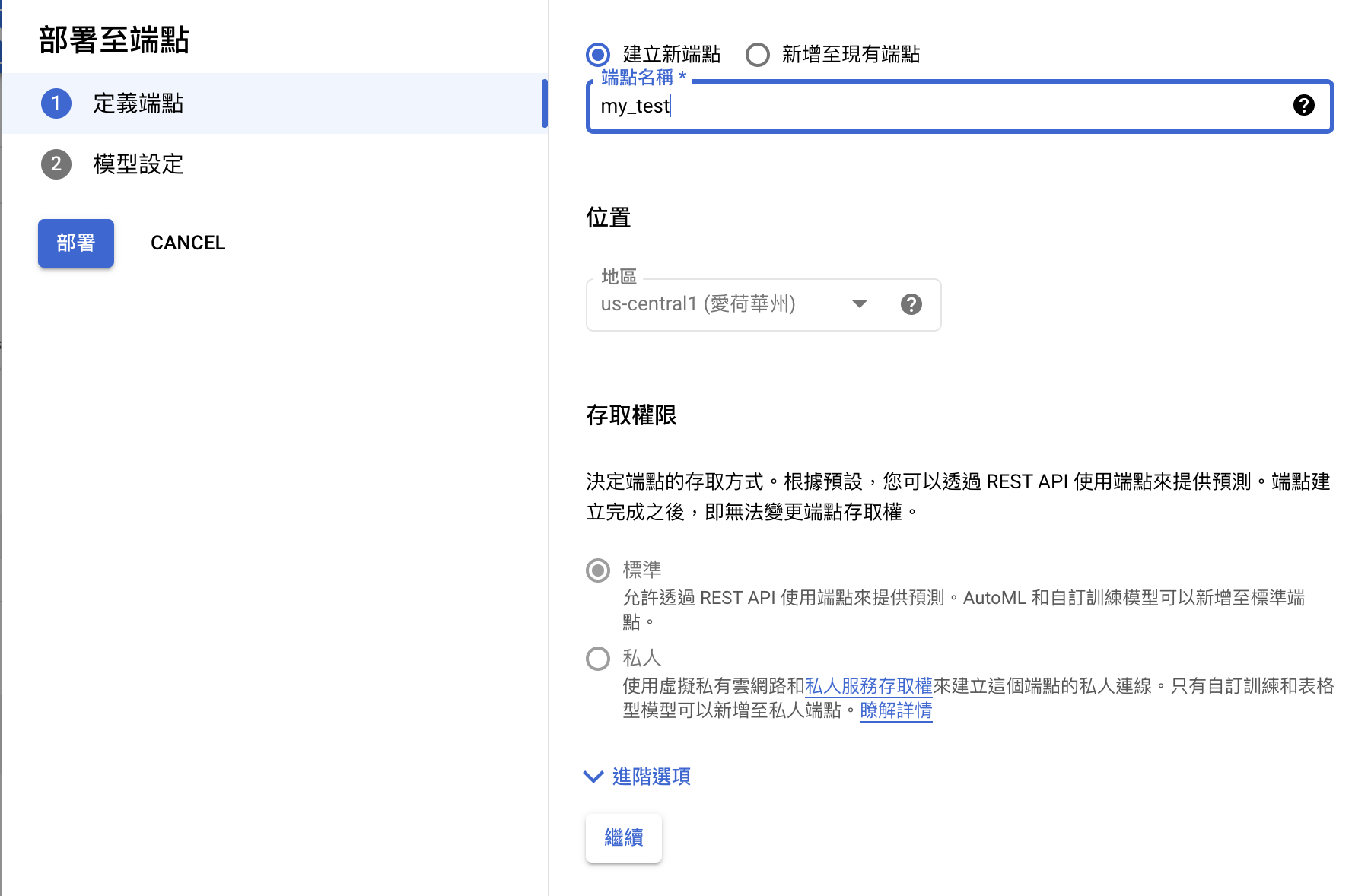
a. 建立端點
因為我們尚未創建端點,因此點選「建立新端點」,並輸入端點名稱
b. 部署所選模型
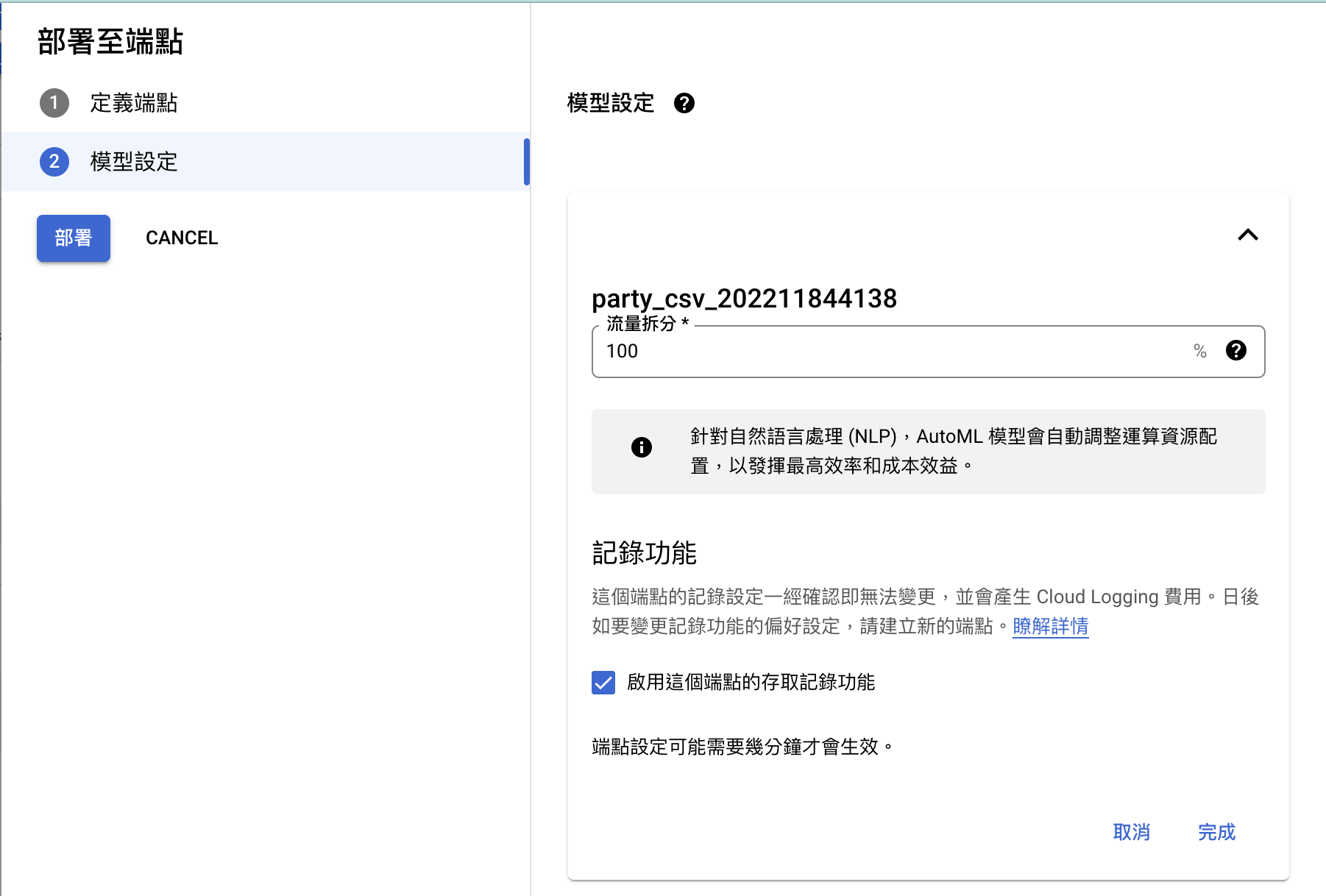
模型設定部分,因為我們只有一個模型,因此全部的流量都需傳入此模型,如之後有其他模型可再修正。如未有更動可直接點選「部署」,如有更動則需點選完成再點選「部署」。
c. 預測測試
模型部署完成後,便能在底下欄位測試結果。我們選擇兩篇文章來進行測試,民進黨選擇鄭運鵬的臉書貼文,非民進黨選擇徐巧芯的臉書貼文。兩篇文章都能準確預測其政治傾向。


從實作的過程中就可以發現 AutoML 操作簡單,預測準確性也夠高。然而,耗費的時間和金錢也相對較高,因此如果你本身就懂得如何訓練模型,我們會推薦使用 Vertex AI Workbench,這可以有效減少訓練成本。
三、Vertex AI Workbench 實作
假設公司來了一位 NLP 專長的員工,可以幫我們建模分析。這樣我們就可以使用 Vertex AI Workbench,其提供多種的主機規格以及環境,隨選隨用以秒計費的特性,擁有更多彈性,不必花大錢升級實體主機,也減輕環境架設的麻煩。接下來我們就以 Vertex AI Workbench 來實作文本分類。
1. 建立筆記本
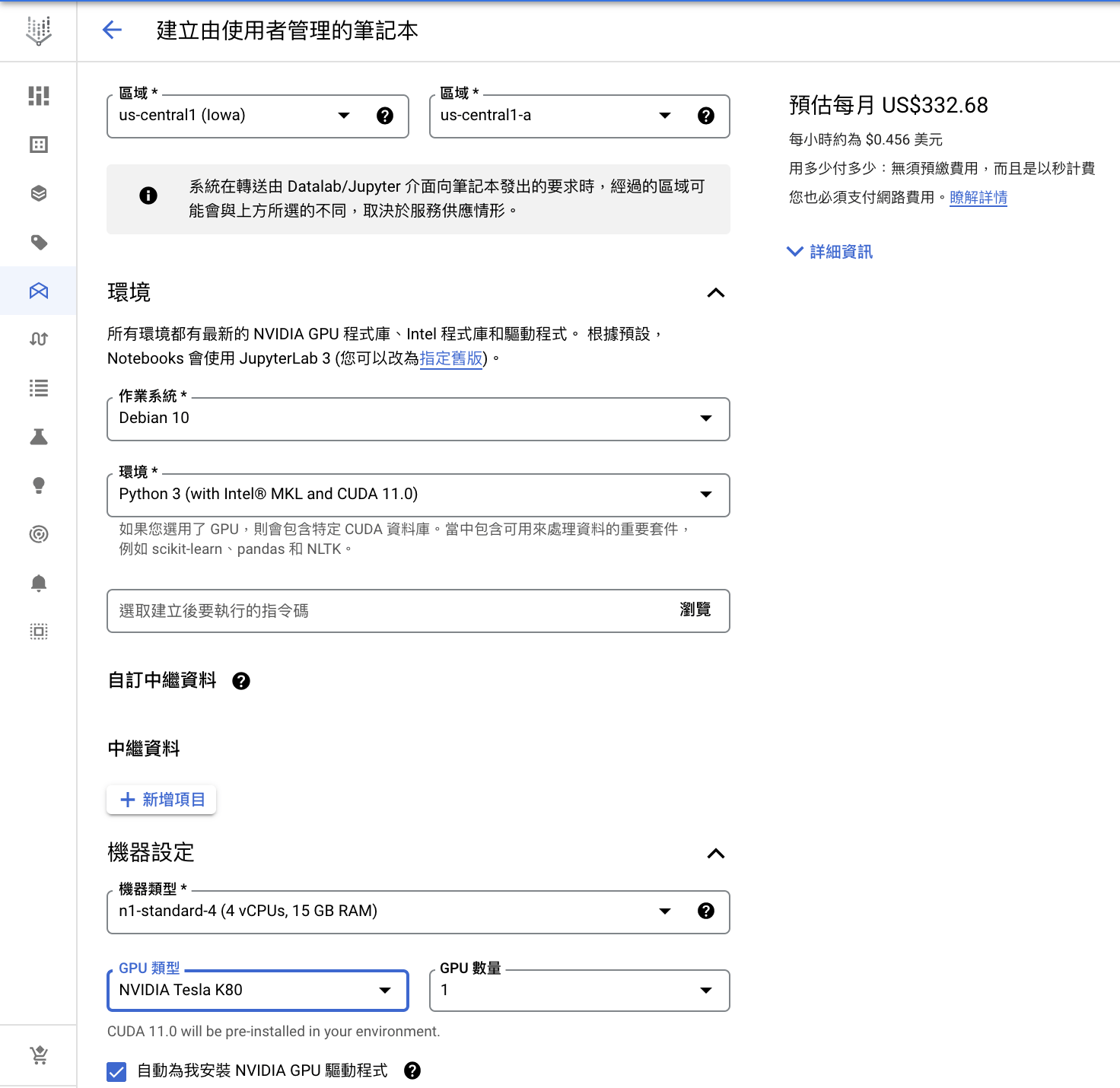
a. 選擇環境:Python 3 (with Intel® MKL and CUDA 11.0)
b. 選擇 GPU:NVIDIA Tesla K80
c. 勾選自動安裝 NVIDIA GPU
2. 進入 Notebook 環境
等待 Notebook 完成後,點選「JUPYTERLAB」進入 Notebook 環境。

3. 上傳文本資料
點選上傳圖示,將 CSV 匯入 Notebook 環境
我們上傳的檔案格式是具有標頭的CSV檔

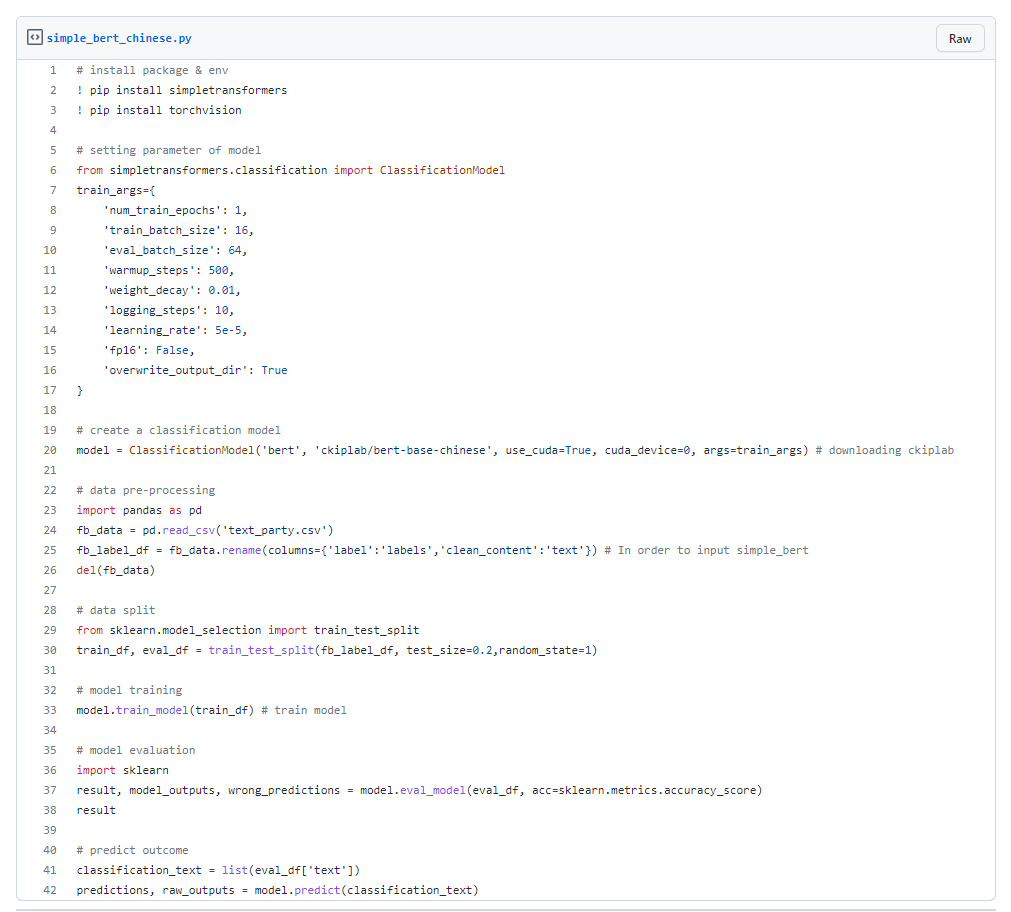
a. 安裝套件(install package & env)
首先我們要先安裝 simpletransformers 和 torchvision 的套件,其他的常用套件 Vertex AI 已經先幫我們裝好了。
b. 模型參數設定(setting parameter of model)
因為只是範例,因此我們的 epoch 次數設為 1,表示我們只會訓練完整的資料及一次。
c. 建立分類模型(create a classification model)
使用 ckiplab 的預訓練模型實作分類模型,use_cuda=True 代表我們將使用 GPU 來進行訓練。
d. 資料前處理(data pre-processing)
使用 pandas 匯入 csv 並進行標頭的更改,因為 simpletransformers 的預設欄位為 text 與 labels。
e. 資料分割(data split)
使用 sklearn 將 80% 資料集作為訓練集,20% 為測試集。
f. 模型評估(model evaluation)
使用 sklearn 進行模型評估,此模型的 Accuracy 約為 0.8,epoch 越高 Accuracy 能更高。
g. 預測結果(predict outcome)
運用此模型來查看測試集的模型被預測為 1(民進黨) 或 0(非民進黨)。
四、總結
| 訓練方法 | AutoML | Workbench Notebook |
|---|---|---|
| 適用對象 | 非 AI 專長的使用者 | AI 工程師 |
| 所需技能 | 能將資料轉換成指定的格式 | AI 模型訓練能力 |
| 使用門檻 | 低 ⭕ | 高 |
| 雲端資源計費 | 高 | 低 ⭕ |
| 模型訓練時間 | 中 | 高或低(取決於使用者) |
| 精確度 | 中 | 高或低(取決於使用者) |
上表簡單整理了 AutoML 與 Workbench Notebook 的優劣勢。Google Cloud AutoML 提供自動化的 AI 訓練,使用門檻低,但費用較貴且耗時較長。至於 Workbench Notebook 雖然使用門檻高,但能讓使用者有更彈性的選擇,如果使用者知道如何有效訓練模型,就能快速訓練出高精準度的模型。相反地,如果使用者不熟 AI 可能會在挑選模型與參數時耗費大量時間,但預測精準度卻差強人意。
因此究竟要使用 AutoML 還是 Workbench Notebook ,仍然需要依照使用者自身的需求來做適當的選擇。AI 模型要實際應用於真實場域,除了要提升模型準確度,整個流程的自動化也很重要,從資料的輸入儲存到模型的預測輸出,Vertex AI 也能搭配其他 GCP 服務來完成,如果想了解這些應用也歡迎來信諮詢。
教你如何用 Vertex AI 實現文本分類
發布日期 : 2022-09 | Jeff
從 0 到 1 教你如何用 AI 進行瑕疵檢測 | Google Cloud Vertex AI
| Google 的機器學習平台 Vertex AI
| Vertex AI – 使用整合式人工智慧平台中的預先訓練和自訂工具,加快建立、部署及擴充機器學習模型的速度
